Dealing with NA values while summarizing
Introduction
NA are missing values or not applicable columns in data. You can read more about NA here. We need to handle the NA values before summarizing or else the summarized outputs will be NA as well.
We set the na.rm argument to TRUE while summarizing. By setting this argument we remove all the NA values from our dataframe and then perform summarization function.
Procedure
We will be working with a custom dataframe.
# package for creating dataframe
library(tibble)
# tibble or dataframe
df <- tibble(col1 = as.integer(c(1,2,3,4,5, 6)),
col2 = c(11,12,13,14,15, NA)
)
View(df)Few rows of the data are:
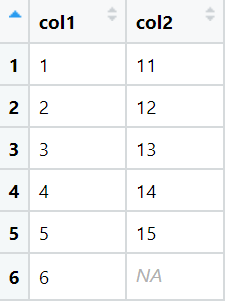
We will perform summarization while setting the na.rm argument to TRUE and FALSE and analyze the results.
Code
-
When na.rm = FALSE:
# refer procedure for definition of df
library(dplyr)
# summarize col1 and col2 while setting na.rm = FALSE
result <- summarize(df, mean_col1=mean(col1, na.rm = FALSE), mean_col2=mean(col2, na.rm = FALSE))
View(result)The output of above code is:
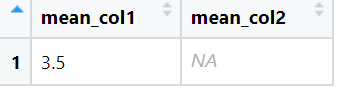
When na.rm = FALSE, which is the default value for na.rm, the summarized value is NA.
-
When na.rm = TRUE:
# refer procedure for definition of df
library(dplyr)
# summarize col1 and col2 while setting na.rm = TRUE
result <- summarize(df, mean_col1=mean(col1, na.rm = TRUE), mean_col2=mean(col2, na.rm = TRUE))
View(result)The output of above code is:
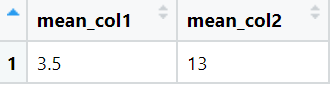
When na.rm = TRUE, the NA values are removed and then the summarization is performed, thus we get the mean value of 13 for col2.
Conclusion
Thus we have successfully handled NA values while summarizing data.
References
- https://r4ds.had.co.nz/